機械学習にてlightGBM等のモデルを使用する際には文字列データをlabel encodingやcategory encodingにて数値データに変換する必要があります。
文字列のデータだけを取り出すのはどうすればよいのか
kaggleのTitanic号のデータをもとにやっていきます。
データの確認
データの変換の前にどのcolumnが文字列のデータなのかを確認しておきます。
import pandas as pd
import numpy as np
df = pd.read_csv('data/src/titanic.csv')
df.info()表示結果
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB
dtypes: objectが文字列のデータ、float64、int64が数値データだと思っていただければOKです。今回は[‘Name’, ‘Sex’, ‘Ticket’, ‘Cabin’, ‘Embarked’]が文字列のデータのようです。
DataFrame.iteritems()を使用する
iteritems()メソッドを使用することで各列ごとの列名とその列のデータ(series)を取得できます。
for col_name, item in df.iteritems():
print(col_name)
print(item)表示結果
PassengerId
0 1
1 2
2 3
3 4
4 5
...
886 887
887 888
888 889
889 890
890 891
Name: PassengerId, Length: 891, dtype: int64
Survived
0 0
1 1
2 1
3 1
4 0
..
886 0
887 1
888 0
889 1
890 0
Name: Survived, Length: 891, dtype: int64
Pclass
0 3
1 1
2 3
3 1
4 3
..
Name: Pclass, Length: 891, dtype: int64
Name
0 Braund, Mr. Owen Harris
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
2 Heikkinen, Miss. Laina
3 Futrelle, Mrs. Jacques Heath (Lily May Peel)
4 Allen, Mr. William Henry
...
略
...
886 NaN
887 B42
888 NaN
889 C148
890 NaN
Name: Cabin, Length: 891, dtype: object
Embarked
0 S
1 C
2 S
3 S
4 S
..
886 S
887 S
888 S
889 C
890 Q
Name: Embarked, Length: 891, dtype: object
itemはseriesなのでそのtypeを取得するためには
for col_name, item in df.iteritems():
print(col_name)
print(item.dtype)
print('===')PassengerId int64 === Survived int64 === Pclass int64 === Name object === Sex object === Age float64 === SibSp int64 === Parch int64 === Ticket object === Fare float64 === Cabin object === Embarked object
あとはこのtypeがobjectかどうかで振り分けられます。
# 格納用の配列を準備
numerical_col = []
not_numerical_col = []
for col_name, item in df.iteritems():
if item.dtype == object:
not_numerical_col.append(col_name)
else:
numerical_col.append(col_name)
print('not_numerical_col:', not_numerical_col)表示結果
not_numerical_col: ['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked']
ちなみにリスト内包表記を用いて
numerical_col_one_liner = [col_name for col_namem, item in df.iteritems() if item.dtype != object]
not_numerical_col_one_liner = [col_name for col_namem, item in df.iteritems() if item.dtype == object]と書くこともできます。
DataFrame.select_dtypes()
特定のデータ型の列だけを取得するならもっと便利なメソッドがあります。
引数 include に取得したいデータの型を指定します。
pandas.DataFrame.select_dtypes
df.select_dtypes(include=object)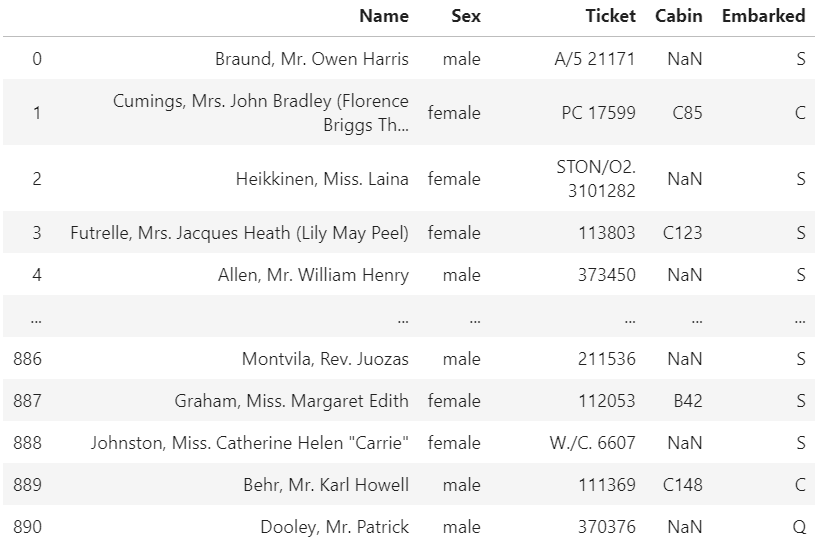
こっちのほうがめちゃくちゃ楽ですね。
逆に数値データだけを取得したい場合は引数に np.numberか’number’を指定すればよいようです。
df.select_dtypes(include=np.number)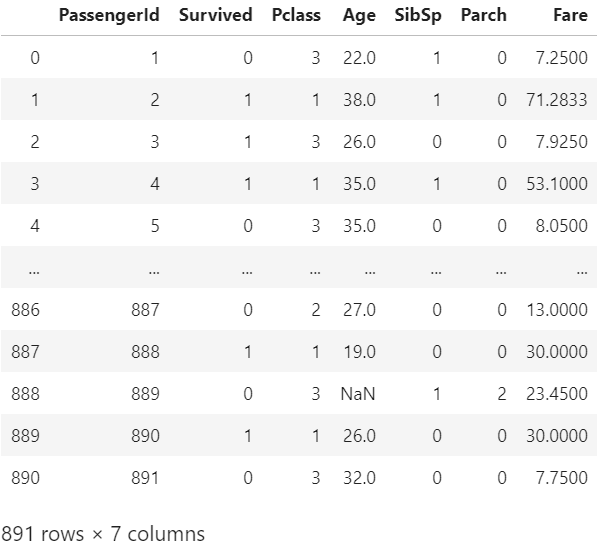


コメント